With the massive resources and strategies accessible to attackers, countering Denial of Service (DoS) attacks is getting increasingly difficult. One of these techniques is application-layer DoS. Due to these challenges, network security has become increasingly more challenging to ensure. Hypertext Transfer Protocol (HTTP), Domain Name Service (DNS), Simple Mail Transfer Protocol (SMTP), and other application protocols have had increased attacks over the past several years. It is common for application-layer attacks to concentrate on these protocols because attackers can exploit some weaknesses. Flood and “low and slow” attacks are examples of application-layer attacks. They target weaknesses in HTTP, the most extensively used application-layer protocol on the Internet. Our experiment proposes a generalized detection approach to identify features for application-layer DoS attacks that is not specific to a single slow DoS attack. We combine four application-layer DoS attack datasets: Slow Read, HTTP POST, Slowloris, and Apache Range Header. We perform a feature-scaling technique that applies a normalization filter to the combined dataset. We perform a feature extraction technique, Principal Component Analysis (PCA), on the combined dataset to reduce dimensionality. We examine ways to enhance machine learning techniques for detecting slow application-layer DoS attacks that employ these methodologies. The machine learners effectively identify multiple slow DoS attacks, according to our findings. The experiment shows that classifiers are good predictors when combined with our selected Netflow characteristics and feature selection techniques.
Network cyber-attacks have become commonplace in today’s world. These attacks have become very sophisticated and challenging to prevent. Many stealthier attacks target the application layer, where they take advantage of vulnerabilities in web servers [1]. Because web servers are open to the public, they are accessed frequently by many users. The attackers’ goal is to simulate legitimate, normal traffic as closely as possible, which they do well. The task for those defending the networks is to determine the difference between normal and attack traffic. Making it even more of a challenge, the attackers are constantly updating their attack methods. One approach to assisting network security personnel is machine learning. Networks have enormous amounts of data they collect. The data comes from various sources, such as logs, Full Packet Captures (FPCs), and Netflow traffic. Machine learning can use data from these sources as input for machine learning algorithms. Also, algorithms have many options that can optimize that algorithm for a given scenario.
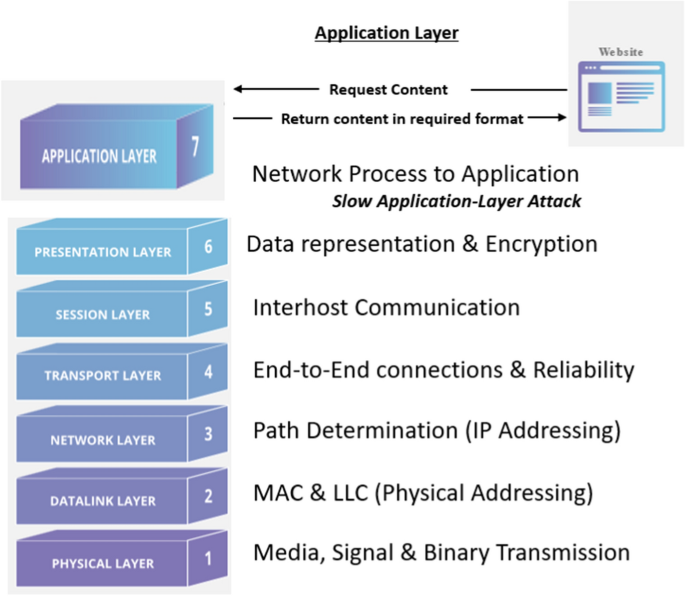
Additionally, there are techniques used to enhance the data before the machine learning algorithm is applied. After collecting the data, the next step is data cleansing, followed by the machine learning process. Selecting the most relevant attributes, commonly referred to as features, generally improves the machine learner’s performance. One must keep in mind that a set of features that perform well with one machine learner may not perform well with another machine learner. Discovering the correct set of features for machine learning is referred to as feature selection. The goal of feature selection is to determine characteristics that will produce the best accuracy and predictability for the machine learner. Network attacks come in many varieties, each of which operates at different layers, with slow Denial of Service (DoS) attacks operating at the application layer as shown in Fig. 1. Our work concentrates on multiple application-layer DoS attacks in this study. User applications receive network services from the application layer. Protocols that operate with user data are known as network services. At the application level, web browsers rely on the Hypertext Transfer Protocol (HTTP) protocol to compress data sent to and received from a web page.
In recent years, DoS attacks targeting application protocols have been on the rise [2]. HTTP, Domain Name Service (DNS), Simple Mail Transfer Protocol (SMTP), and other application protocols have increased attacks over the past several years. It is common for application-layer attacks to concentrate on these protocols because attackers can exploit some weaknesses [3]. Attacks targeting application resources can take various forms, such as HTTP GET, HTTP POST, Slow Read, and Apache Header attacks. The HTTP protocol contains weaknesses that attackers exploit when employing low-level and slow-moving tactics. A low-and-slow attack targets application or server resources with a modest stream of persistent traffic. Low and slow assaults, unlike more standard brute-force attacks, need extremely little bandwidth. They can be difficult to counter since their attack traffic blends in nicely with normal traffic, making it impossible to discern between the two.
To circumvent intrusion detection systems, attackers employ a variety of evasion techniques that expose the network’s DoS vulnerabilities. Evasive DoS techniques will secretly affect ordinary online services without causing any alarms. The use of flow-based (Netflow) analysis is one such option. Netflow, often known as session data, is a high-level representation of network traffic. A conversation is represented by a five-attribute network flow record. The IP addresses for the source and destination, as well as the source and destination ports, are listed first, followed by the transport protocol [4]. The System for Internet-Level Knowledge (SiLK) [5] is a collection of Netflow session data generation and analysis tools. SiLK is capable of collecting Netflow data as well as converting FPCs to Netflow. Netflow consumes a disproportionately smaller amount of storage than FPCs. Due to the smaller size, it is possible to parse flows quickly and effectively without requiring a lot of CPU power. Netflow is critical when it comes to server memory and hard disk requirements. Netflow also makes use of well-designed features to prevent attackers from using evasion techniques [6].
In this study, we made three distinct contributions. The first involves examining multiple application-layer DoS attacks using Netflow features and machine learning predictive models to detect them. Predictive models are built using these features with six learners to detect evasive, slow application-layer DoS attempts. The six machine learning approaches are: Random Forest (RF), C4.5D and C4.5N decision trees, 5-Nearest Neighbors (5NN), Naive Bayes (NB), and JRip, which uses repeated incremental pruning to reduce errors. Based on our previous experience with network data and its diversity, we selected these classifiers. The six machine learners provided us with a diverse set of algorithms to integrate with our Netflow features. The Netflow features take advantage of the Internet Protocol Flow Information Export (IPFIX) [7] protocol’s scalability and adaptability to a variety of scenarios.
The integrity of our data is the subject of our second contribution. Other studies have gathered data through the use of simulations, testbeds, and software-generated traffic [8, 9]. We get data from a production computer network’s real-world network. Regular traffic aids in the representation of outcomes in a live network context. Attacks were produced on a functional, live platform. We created four application-layer DoS assaults by modifying variables in each attack utilizing three tiers of concurrent connections, giving us a broad range of attacks with represented models that mirror real-world behavior. Because we provide our data in a live setting rather than simulated environments or testbeds, we can demonstrate its quality and integrity. When collecting data on a live network, there are a few obstacles to overcome. The creation of sufficient normal data, the concern for information privacy, the implementation of attacks on a live network without disruption, computers required to attack at the same time, and network management are all challenges. Because of these difficulties, other related fields frequently rely on publicly available databases [10, 11].
Feature selection is our third contribution. We employ selective feature evaluation and investigate several methods used to specify the attribute evaluators and search methods. We evaluate the significance of a subset of attributes by a feature’s predictive ability and the amount of duplication between them. Highly correlated feature subsets with the class while having low intercorrelation are preferred. For this experiment, we chose the Weka [12] feature selection methods CfsSubsetEval, ConsistencySubsetEval, and ClassifierSubsetEval. We also used Weka functions for single-attribute evaluation, such as ChiSquaredAttributeEval, GainRatioAttributeEval, and Principal Component Analysis (PCA), which is a feature extraction technique. When combined with the Ranker search method, ChiSquaredAttributeEval and Gain-RatioAttributeEval rank individual characteristics according to their assessment. Unlike other single-attribute evaluators, PCA transforms the given set of attributes into newly created subsets of its own.
The highlights of our research are as follows:
The following is how we ordered our paper. We go over standard slow application-layer attack methods, tools, and data types in “Background” section. In “Related works” section, we go over some of the other research that has been done on gathering and identifying delayed application-layer DoS HTTP attacks. Our data gathering techniques and experimental designs are described in “Experimental procedure” section. “Results” section is a discussion about our results, and “Conclusion” section is our conclusion and future work.
There are a variety of methods for enacting an application-layer DoS attack. Contingent on the characteristics of the network, various types of attacks are chosen based on the targeted traffic. In this section, we detail the slow application-layer attacks, data collection process, and Netflow traffic.
DoS attacks are difficult to trace due to their evasive techniques. Attackers will impersonate IP addresses to mask their origin, making DoS tracking difficult. Furthermore, the number of attacks focusing on the application layer is expanding at an alarming rate. When deploying a comprehensive Distributed Denial of Service (DDoS) defense, it is important to understand all the aspects of the DDoS attack mechanism. Over the past several years, researchers have offered numerous types of DoS attacks in their work.
Unlike high-bandwidth flooding assaults [13], low-bandwidth application-layer attacks focus on staying below the radar to evade discovery. Application-layer attacks do not require a huge number of bots and can be carried out on a single computer. When compared to traditional flooding attacks [14], these attacks use less bandwidth. The network traffic seems to be valid when a web browser is used to create a connection to servers using HTTP request messages. The server will then accept the connection and respond to HTTP queries with HTTP response messages. It’s difficult to tell the difference between an attack and typical traffic, and it takes experience in the field.
HTTP POST or HTTP GET queries are popular methods used in attacks on the application layer, exhausting web servers’ resources. The routers assess the entire transmission to see whether there has been a sudden increase in the detection of DDoS flood attacks. After locating the problematic router or server, administrators take steps to remove the threat. Attackers increasingly target HTTP, DNS, and SMTP services. Some of these attacks can be successful as compared to others if they require fewer network connections.
Regular expression DoS or ReDoS attacks employ a specifically constructed message to exploit a flaw in a server-side software library. The flaw allows the server to spend its resources while computing a regular expression from user input or performing a sophisticated regular expression attack.
Hash collision attacks are designed to exploit common security flaws in Web application frameworks. Hash tables are created on application servers to index POST session parameters. When returning comparable hash values, application servers must manage hash collisions. Collision resolution operations consume additional CPU time, such as when an attacker submits a POST message with a high number of arguments in a hash collision DoS attack scenario. Collisions of a Hash DoS attacks are extremely successful and may be performed from just one machine, gradually depleting the resources of the server.
Slow application-layer DoS attacks focus on services and vulnerabilities, enabling the attack to cause a denial of service without being discovered. The attack is based on a short burst of traffic that targets application or server resources. Application-layer attacks performed with the Transmission Control Protocol (TCP) connection enable the attack through regular network traffic as a valid connection. TCP is a dependable protocol that checks for mistakes and assesses if packets have been received throughout the communication between two machines. By receiving the server’s response gradually and employing a short TCP window size, slow application-layer DoS attacks maintain an open line of connection. The TCP protocol’s Request for Comments (RFC) 1122 [15], in which the receiver advertises zero-byte windows. The sender does not need to provide any further data to keep the communication tunnel open. By activating a zero-byte connection window, the target has created a vulnerability for a slow application-layer DoS attack.
While large-scale DDoS assaults are more likely to be identified immediately, low and slow level attacks can go undetected for lengthy periods of time while denying or degrading service to legitimate customers. Customers who purchase products and require access to internet accounts at anytime of day expect networks to have fast and efficient accessibility for their daily operations. Because of the widespread reliance on this access in today’s networks, malevolent attackers have turned their attention to this type of server. DoS attacks are designed to prevent customers and employees from receiving services. The methods utilized in application-layer DDoS assaults are listed below.
HTTP flood attacks are the most common DDoS attacks targeting application resources. These attacks look like normal HTTP GET or POST requests to a victim’s Web server, rendering them difficult to identify. HTTP flood attacks often include numerous computers (bots). These bots repeatedly request pages from the target site, triggering a DoS condition. The High Orbit Ion Cannon (HOIC) tool enables the execution of multi-threaded HTTP flood assaults in an easy-to-use manner.
A malicious HTTP GET request monopolizes the server’s capabilities by using a large number of open connections. The available connections eliminate the requirement for services to consumers to establish authentic relationships. The attacker produces and transmits partial HTTP GET requests to the server, causing each connection request to be opened in a separate thread. The attacker transmits HTTP header data infrequently to ensure connections remain open and do not time out. Because the transmission occurs slowly, the server has to wait indefinitely, emptying the connection table and resulting in a DoS. HTTP GET-based attacks are easier to generate and can more efficiently scale in a botnet scenario.
Another attacking approach in this content is the Slowloris attack. The Slowloris attack bases itself on the weakness of an HTTP GET request. A delaying method is used in an HTTP GET header assault to alter timing. The attacker will not transmit all HTTP GET request headers concurrently, but rather divide and send each line separately. The server establishes communication with the malicious attacker and allots time for dialogue.
Application-layer DoS attacks like Slowloris, Slow HTTP POST, Slow Read, and Apache Range Header drain the concurrent connections pool, leading the server to use a lot of memory and CPU. Most thread process-based HTTP servers (e.g., Apache) are vulnerable to this type of attack. Attackers can perform Slow HTTP POST attacks by issuing a lot of concurrent POST requests, and each of them will slowly send the POST body [16]. The attacker detects forms on the web server and sends HTTP POST requests to the web server via the forms and applies the Slow HTTP POST attack. Instead of being sent in bulk, POST requests are delivered one byte at a time. When an attacker sends a slow HTTP GET request, the attacker keeps the vulnerable connection open by progressively sending fresh bytes of POST data at regular intervals. Given the length of the HTTP POST request’s content, the server is forced to wait for the entire POST request to be received. The attacker repeats this activity in parallel, never closing a connection that is open. After several hundred connections are established, the target server becomes incapable of handling new requests, resulting in a DoS issue.
The Apache Range Header attack takes advantage of an Apache HTTP Server’s binary filter, allowing a malicious attack to launch a DoS attack through a range header expressing numerous intersecting scales [17]. A remote attacker can slow down or exhaust the resources of the service or server, rendering it incapable of responding to legitimate clients in a timely manner. The result of this vulnerability produces the result of a DoS. The server is unable to service any requests and refuses any additional connections. Using the SlowHTTPTest tool [18], a simple command generates a HEAD request with a header range of 0-, x-1, x-2, x-3, x-y where x is set by -a argument, y is set by -b argument and increments by 1 byte. The test works with various connection rates and numbers over Secure Sockets Layer (SSL).
This subsection briefly presents an overview of the primary attack tools used to execute application-layer attacks while staying under the radar. The development of specific attack tools focuses on performing attacks more efficiently and quickly.
The Orbit Ion Cannon is an offensive weapon available in two configurations: high and low. Both simplify the execution of multi-threaded HTTP flood assaults. Low Orbit Ion Cannon (LOIC) [19] can produce a substantial volume of TCP, User Datagram Protocol (UDP), or HTTP traffic that can overload a server and bring down a network. HOIC [20] is a software tool that leverages a simple Graphical User Interface (GUI) to inject HTTP POST and HTTP GET requests. An attacker can build Uniform Resource Locator (URL) lists and specify content for HOIC to traverse through as it produces DoS attacks by employing scripts. As a result, defending against these kinds of attacks becomes slightly more difficult. HTTP headers are transmitted to the destination server in tiny chunks.
R U Dead Yet (RUDY) [21] is a tool similar to Slowloris. RUDY launches a DoS attack by submitting HTTP POST requests using a field from the long-form field instead of HTTP headers injecting data into the POST field one byte at a time, resulting in a significant bottleneck of application threads. The long “Content-Length” field prevents the server from closing the connection. An attacker can create several connections when communicating with a server, eventually emptying the connection table, thus resulting in a DoS condition.
Botnets aid DDoS tools in launching attacks from a distributed network of computers. Whether there are hundreds, thousands, or millions of botnets, they dramatically increase the possibility of a DoS attack. Botnets are widely used by attackers. Botnets are massive networks of infected computers, frequently dubbed “zombies.” This enables an attacker to exert control over them. Botnet operators can command and control botnet devices by delivering commands to perform harmful acts using a covert channel, such as Internet Relay Chat (IRC). DDoS attacks, spam mail distribution, and information theft are all examples of such actions.
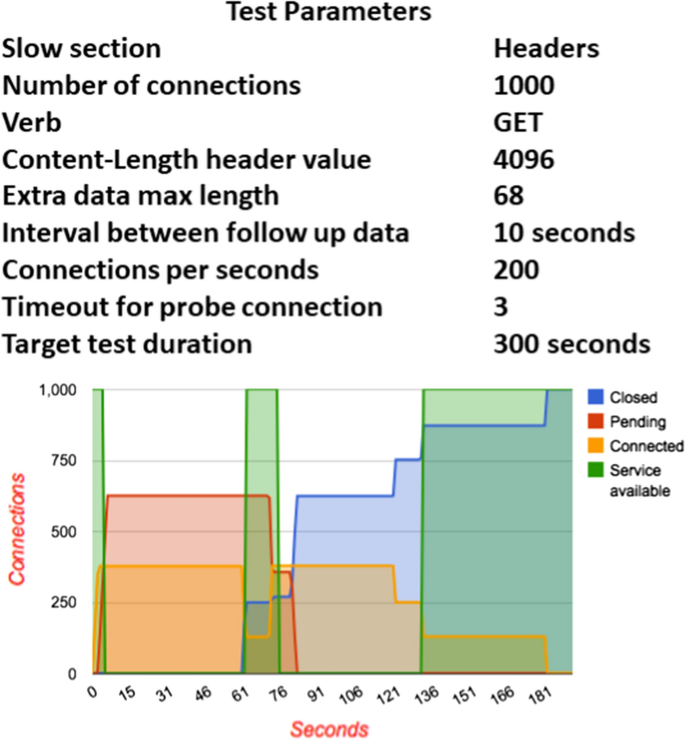
The attack methods previously stated can be carried out using the SlowHTTPTest software [22]. Slowloris, Slow HTTP POST, Slow Read, and Apache Range Header are among the application-layer DoS techniques that it effectively implements. Slow application-layer attacks target web servers that do not enforce connection timeouts. Concurrent connections are what bring the server down in the end. The SlowHTTPTest utility is seen in Fig. 2 enacting a Slow Read DoS attack.
There are numerous tools available for capturing, parsing, and analyzing both FPC and Netflow data. T-shark [23] is a network protocol analyzer that comes included with Wireshark. T-Shark collects and analyzes network traffic (pcap files). Pcap is an application programming interface for network traffic capture. Tcpdump [24] is a popular packet analyzer that shows packets sent or received across a computer’s network connections. Additionally, Tcpdump allows for the saving of packet contents to a file for later examination. Cisco’s products use Netflow version 9 [25] for network traffic accounting, security, DoS monitoring, and general network monitoring.
Another open-source product used for Netflow collection is Nfdump [26]. The subset of software tools in Nfdump can collect and process Netflow data. It collects Netflow data via Nfcapd-stored records and analyzes as per the parameters specified. Nfdump supports Netflow versions v1, v5, v7, v9, and IPFIX. In our experiment, we used Dumpcap [27] and the SiLK tool suite for collecting FPC and Netflow data.
Zargar et al. [28] classify distinct types of DDoS flooding at the application layer. At the Open Systems Interconnection (OSI) network and transport layers, flooding attacks based on reflection amplification occur. The strategies used in these attacks are the same as those used during application-layer attacks. HTTP flooding attacks consume a greater portion of the attacker’s session connection request rates than legitimate user requests. HTTP GET/POST flooding is a well-known example of this type of attack, wherein the attackers send a large number of legitimate GET/POST requests to the targeted web server. Attackers submit sessions with more requests than normal, leading to a DDoS flood attack disabling the server.
Attackers utilizing image processing methods breach CAPTCHA codes [29]. The noise in the background is eliminated from the CAPTCHA image before it is separated for verification. These images consisting of background noise make them difficult to detect by machine-based recognition. But such material often renders photos hard to read by people. The consequence of these actions can cause legitimate users to grow irritated, and services given may be restricted.
Publicly available datasets have been used in research on application-layer DDoS like [30,31,32], but they are outdated logs. The authors of all three studies collected the first and second logs in 1995 for 7 days. Other captured public datasets were collected in 1998. As a result, it is devoid of traffic generated by new apps or abnormalities. [10] focus on backbone traffic anomaly detectors and provides labeled backbone traffic in the absence of packet payloads and flows that are incomplete or asymmetric. Their approach aims to mitigate undiscovered hostile traffic that masquerades as legitimate traffic and to design a customized anti-DDoS module for general and specific DDoS tool attacks by incorporating a taught classifier into a random tree machine learning method.
Chengxu et al. [33] developed and provided a publicly available dataset, representing one 24-h day of log-only traffic. One day is just a snapshot of what was happening that day. Multiple-day logs would have to be collected and averaged for better results to represent what took place accurately. Also, this dataset is just a log and does not represent a full packet capture, which would help in a more in-depth analysis.
Simulations at layer seven (of the OSI) and application-layer DoS attacks sometimes employ valid IP addresses and imitate lawful queries [34]. By injecting malicious payloads into their dataset, [35] formalize their assault and normal traffic on the server. The authors demonstrate the capacity of the statistical model checker PVeStA to thwart application-layer DDoS attacks using a defense mechanism and a computational system called Maude.
Vijayalakshmi et al. [34] conducted application-layer DoS attacks via packet header processing. These assaults typically employ genuine IP addresses, imitate normal requests, attack or destroy the server with a damaging payload, and use worms to form a botnet. Their work is being implemented in the National Technical Research Organization’s Smart and Secure Environment Test Bed. Classification is performed using non-flooding application-layer attacks on simulated models. To utilize the Mahalanobis distance, we compare two statistical distributions. This is a standard distance metric. They then compute the distance between the newly observed payload’s byte distribution and the profile computed from the model for the relevant length range. The greater the distance score, the more suspicious this payload is.
Yadav et al. [36] used HTTP requests which attack the nitt.edu web server with the same attack dataset used in their testbed. A switch is utilized, connecting approximately 100 PCs to the webserver as two bots use Java LOIC and Golden Eye Master for the attack. All incoming traffic towards the webserver is captured using traffic capture software. This provides them with three various attacks. Though they should be complimented for their work, we believe improvements can be made by collecting attacks and normal traffic in a live environment instead of a testbed. This would provide a better representation of overall traffic for the datasets. In addition, along with logs from the server, full packet captures would give more in-depth datasets to use for analysis on their own and as a comparison to log datasets.
Durcekova et al. [37] discussed the use of HTTP GET and POST to exploit the HTTP protocol’s weaknesses. The attacker sends a large number of malicious HTTP GET requests to the target server in this sort of attack. Due to the fact that these packets contain genuine HTTP payloads, vulnerable servers are unable to discriminate between legitimate HTTP GET requests and malicious queries. As a result, servers must handle all requests as normal requests, eventually exhausting their resources.
Stevanovic et al. [38] initiated three possibilities of assault. Initially, the attacker compiles a list of directly available websites from the website’s home page via a single URL. Following that, the attacker generates a surfing sequence by selecting randomly from this list of pages. The second attack estimates the popularity of a page by contacting the Google search engine. The third stage builds an attack sequence from the website’s index.html page and subsequent pages. They are ordered randomly via a connection between web pages.
Devi et al. [39] proposed a scheme to defend against DDoS attacks in the application layer and schedule the flash crowd during these attacks. Their main goal is to stop suspicious traffic and provide services to legitimate users. HTTP GET flood requests and perform massive file downloads from the victim server.
An architectural improvement, known as CALD that defends Web servers from multiple DDoS attacks masked as flash crowds, is described by Wen et al. [40]. The first assault, dubbed “repeated request DDoS”, organizes numerous infected computers by continually sending queries to the website’s homepage. MyDoom and Code Red are all examples of this type of DDoS attack. The second method creates a list of premium pages and picks one at random for every HTTP GET request. The third method targets HTTP GET queries. This DDoS attack with recurring loads requires less effort from the attacker as well as being harder to detect.
Chwalinski et al. [30] used HTTP GET attacks using sequences of requests to limit the accessibility of web servers. They assume that sequences of requests provide enough information for detection. Therefore, numerous methods have been developed that attempt to learn legitimate behavior from weblogs. The authors also define a clustering algorithm used for legitimate sequence grouping. Attacking host techniques are shown that closely resemble human agents. This clustering algorithm’s performance is hard to emulate. Statistical measurements to identify attacker hosts are then presented, along with their detection accuracy.
Xu et al. [41] utilized a unique user behavior-based detection approach to detect application-layer asymmetric DoS attacks. Asymmetric attacks deliver requests that require a lot of work, such as dynamic interactive pages, database queries, and sophisticated script requests. A more covert attack occurs when attackers manage numerous workstations spread across a large area, use legitimate high workload requests, and use the actual IP address. The rate of request attacks is not always greater than that of authorized users. Their requests are frequently disguised as normal ones. Asymmetric attacks are difficult to detect using present approaches.
Singh et al. [42] investigated the effect of application-layer DDoS attacks on web services utilizing the NS2 simulator’s web cache model. They launch an application-layer DDoS attack against the webserver with an NS2 simulation using the webcache/webtraf model. Twenty attackers start at a short random time. The 20 clients are regarded as bots capable of making HTTP request/response traffic at 800-s intervals. The duration of the whole attack is 700 s, i.e., the attack runs from 800 to 1500 s. NS2 simulations lack a real-world environment that would provide an accurate picture and reliable data from actual networks.
Vlajic and Slopek [43] used so-called Puppetnets to launch application-layer DDoS attacks. Their other attack spreads web bugs via email. Puppetnets are a collection of HTML/JavaScript commands that are inserted into the HTML/JavaScript code of a high-traffic, otherwise legitimate-looking website. DDoS attacks employ spam email with web bugs to hijack the browsers of legitimate people. A web bug inserted in an email enables the sender to track the precise time the email was opened for the first time and then revisited.
Stevanovic et al. [44] conducted three synthesized attacks categorized and employed in their work. “Trivial Attacks” use bots to send standalone HTTP requests with unidentified and banned User Agent Strings (UAS). The exploit distributes independent HTTP requests that contain faked UASs with a harmless crawler. Slow Read and Slow POST are known examples of such attack methods. A semi-random series of HTTP requests from each bot appears to have been produced by a valid Web browser.
Dantas et al. [35] used Maude’s computational tool [45] to launch two distinct DDoS attacks. Maude is a logic-based tool for specifying and analyzing real-time systems in a formal manner. The attacks studied were HTTP PRAGMA as well as an HTTP POST. The PRAGMA HTTP header field is meant for HTTP protocol requests. Updated models of formerly required resources are made accessible to the application and any intermediary libraries. The application receives PRAGMA messages that reset timeouts, allowing the connection to continue, and the receiver’s connection is kept open in the program’s memory. After a client completes the form’s input, the HTTP POST attack sends a request. Its purpose is to tell the webserver about the form’s data input. On getting a POST request, the webserver accepts the form’s content. The attacker sends a POST request to the website providing the data size. Rather than transmitting large chunks of the entry, as legitimate clients would, the attacker sends a little bit of data every message, using the application’s resources for a prolonged period of time.
None of the related works examine multiple application-layer DoS attacks using Netflow features and machine learning predictive models. In addition, we are the first to use feature selection and PCA for application-layer DoS detection.
This section summarizes our experiments involving four slow application-layer attacks, including the data collection approach, dataset aggregation, machine learning algorithms, metrics, data pre-processing, as well as feature selection.
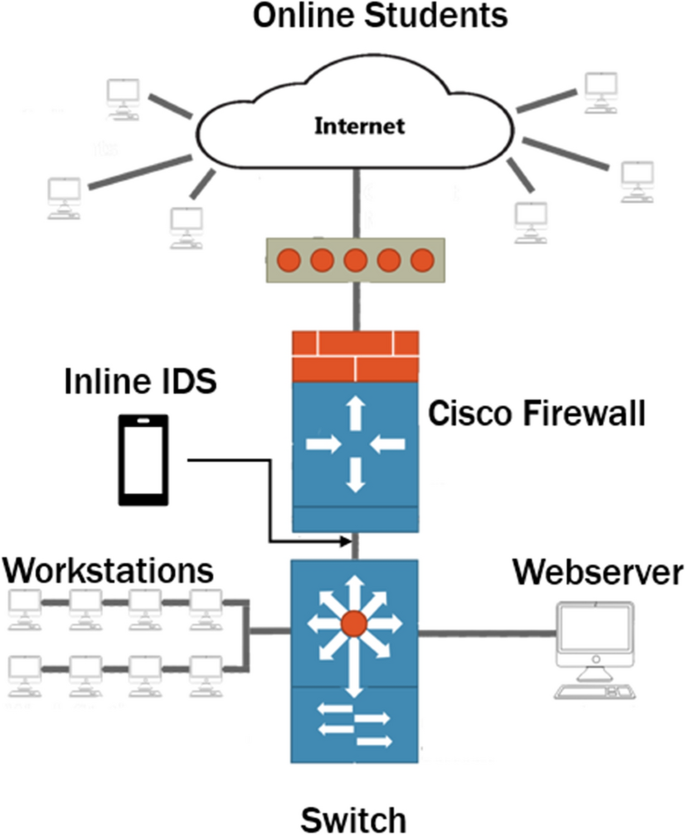
The gathering of Netflow data requires the use of hardware and software to gather, categorize, and save information for processing and tracking. Figure 3 exhibits the network architecture that enables us to carry out attacks on a real-world network with a large number of active users. Downloads, uploads, website navigation, and other web server communications are all considered normal network traffic. They can access course materials from our server both locally and remotely. A firewall protects data and network resources against unauthorized access. On the Apache webserver, student resources have been put up as a target for our attacks. Dumpcap [27], a component of the Wireshark software suite, is used to capture packets on a Linux-based server. Dumpcap is software designed to capture packets from a network and save it to storage. Dumpcap continuously monitors packets and archives recorded packets for later analysis and is frequently the major source of data utilized to analyze network traffic.
Our Netflow data is collected and stored with the SiLk software suite. SiLK collects FPCs and builds network flows. SiLK can convert FPC files to SiLK network flow records and export them as Comma-Separated Values (CSV) datasets for machine learning [46]. Our controlled attacks NetFlow data is analyzed to identify attack classifiers utilizing IP addresses that performed the attack and the remainder as normal. Netflow data does not offer the amount of forensic detail discovered in FPC data. Still, the small size allows it to be retained for a much longer time, which is incredibly valuable when performing an analysis [6]. Netflow provides a lot of flexibility and functionalities that assist with detecting anomalies with flows that have proven effective in detecting DoS evasion strategies. Prior to identifying our data records, a data purification step was required.
We used three datasets (HTTP POST, Slowloris, Slow Read) from previous research and one attack (Apache Range Header) newly created from this study. These four separate attacks represent variations in attack duration ranging from 5 to 60 min time frames. Our study focuses on capturing multiple application-layer DoS attacks against our web server. Our acquired attack data is easily identifiable because the attacks come from the IP addresses we performed in the attack. An attackers’ IP address uniquely identifies (labels) attack traffic, whereas all other instances are considered normal. By integrating controlled attacks, the labeling ensures correct attack labeling. We complete the data cleansing procedure by processing the data using SiLK and exporting it as a CSV file, using Pandas [47] to validate it.
Slowloris attacks are performed on a physical host machine rather than simulated. We choose to use the Slowloris.py attack script for our tests. It was easy to set up and had several attack choices [48]. Our Slow Post attack tool was OWASP Switch-blade 4.0 from the Open Web Application Security Project (OWASP) [49]. We investigated popular alternative tools and settled on OWASP Switchblade due to its flexibility. Instead of a distributed attack, we employed a single physical host machine with numerous connections [48]. Slow Read attacks are performed on a physical host machine with the SlowHTTPTest tool [22]. Variations in settings used by SlowHTTPTest are applied to give us different results and valuable information on the attack thresholds [46, 50]. The SlowHTTPTest tool was also used for the Apache Range Header attack. For more in-depth information on the dataset collection process and environment, please refer to each of these cited works.
All four datasets, Slowloris, Slow Post, Slow Read, and Apache Range Header, were collected by our research team. The aggregated features of the four datasets produced the new dataset for our experiment. The aggregated slow attack dataset has 828,510 instances consisting of 34,097 attacks and 794,413 normal traffic. When comparing each previous dataset to the aggregated dataset, there was no significant impact on performance due to the imbalance in the data. We removed the “attribute” feature because it was an insignificant factor in previous datasets. The difference in the results both with and without the attribute feature was negligible. Eliminating it can also help with overfitting. Table 1 below names and describes the multiple slow attack feature set produced from the four datasets used for our experiments.

Our results for feature selection and machine learner performance are shown in the sections below. We present four different feature selection methods by comparing feature selection methods using six machine learning models. As previously mentioned, the Aggregated Slow Attack dataset has 828,510 instances consisting of 34,097 attacks and 794,413 normal traffic. Our goal is to achieve the same performance or better than the twelve-feature set using feature selection methods. Feature selection does this by focusing on the total number of Type I and Type II errors, with more focus on minimizing the total number of Type II errors. Maximizing the detection of the 34,097 attacks is critical because an incorrect prediction results in a successful attack. Therefore, we focus on operating points by expressing Type II errors in absolute terms to minimize Type II errors to the lowest value while maintaining above 90% F-measure scores and 95% or better AUC results.
Overall, our Netflow dataset results show that Netflow features can distinguish between normal and attack traffic, with five out of six predictive models detecting multiple slow application-layer attacks. Consistent results demonstrate that when paired with Netflow data, classifiers are sufficiently selective to detect multiple slow application-layer attacks.
Normalization creates different features on the same scale via key features. Although values obtained are characteristic of enabled attack types, there is a possibility that our learners may place too much weight on the specific values obtained rather than the overall behavior of the feature in question. Tables 3 and 4 compare slow application-layer attack results before and after normalization. Figures 5 and 6 show the effects on the same branch of a decision trees rule with C4.5D.
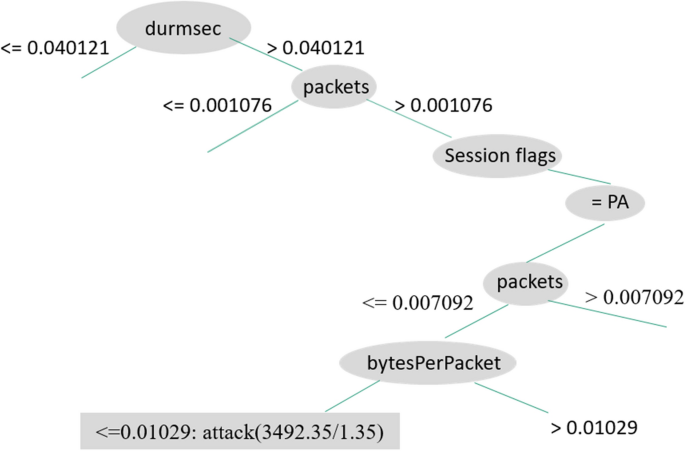
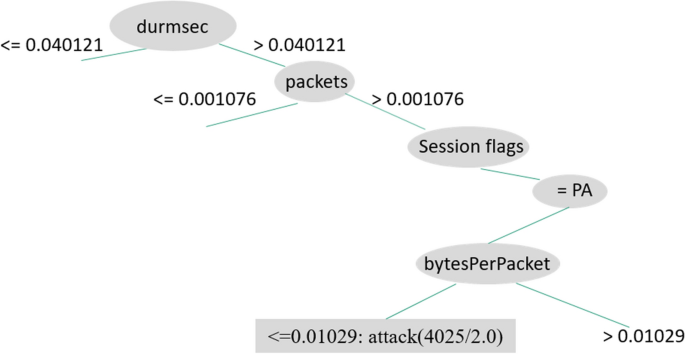
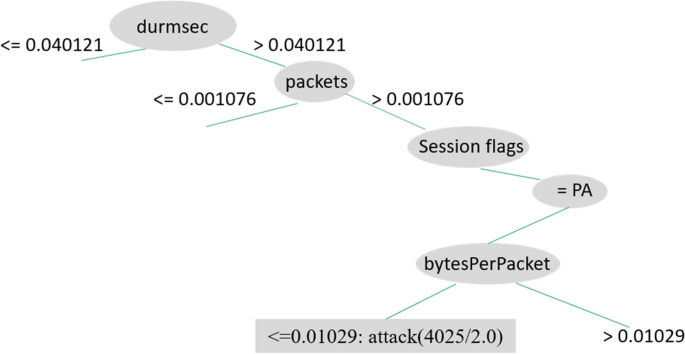
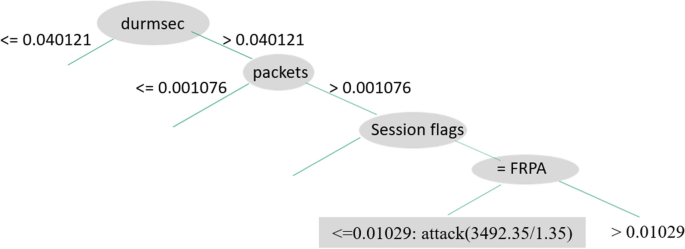
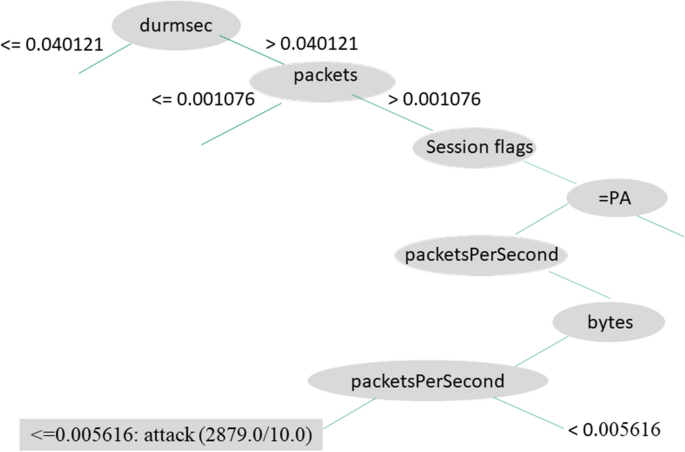
We see the rules generated by C4.5D in Figs. 7, 8, and 9, illustrating three decision tree examples. Durmsec is the only behavior that is consistent between the two. The Durmsec feature is used at the top tier of each of the three trees in the C4.5D model. We can tell the difference between regular and attack flows by their distinct behavior. Shown in Fig. 7, a rule detects an attack when Durmsec has a value greater than 0.040121, packets are greater than 0.001076, and the sessionFlags combination = PA and bytesPerPacket ¡ = 0.01029. Figure 8 has a shorter branch, with Durmsec again being greater than 0.040121 and packets greater than 0.001076, followed by a session flag combination of Finish, Reset, Push, Acknowledgment (FRPA). There are 3492 attack instances. Figure 9 starts again with Durmsec greater than 0.040121, bytesPerSec greater than 0.007724, sessionFlags producing PA, packetsPerSec not more than or equivalent to 0.006304, bytes equal to or more than 0.00079, and packetsPerSec less than or equal to 0.005616, identifying 2879 attacks. Figures 7 and 8 are similar, except for the different values for session flags on the third node. Figure 7 has a Push, Acknowledgment (PA) value with one more node (bytesPerPacket) and Fig. 8 has an FRPA value and ends there.
ANOVA was used to determine whether or not there were statistically significant differences between the means of our six models. As indicated in Table 5, our F-value is 120.8825, and the p-value is less than 6.62e−15, indicating a significant difference between the groups. Based on the 95% confidence interval, our findings show that variation in mean values amongst classifiers has more weight than variation in mean values for all models.
Table 5 ANOVA initial statisticsAs a result, the null hypothesis is rejected. Statistics show a link among learners and slow application-layer DoS attack detection, demonstrating differences are statistically significant. A Tukey’s HSD post-hoc test was used to identify the statistically significant differences between learners. To categorize our models, we used a Tukey’s test. Table 6 shows the top five learners in Group A and JRip in Group B. The classifiers and percentages associated with the various letter clusters are different. This identifies two levels (A and B) of performance groupings within the machine learners. Group A learners, RF, C45N, C45D, 5NN, and NB were significantly better than the other learner JRip from Group B.
Table 6 Tukey’s HSD group initial resultsThe following section shows the results of our experiment when applying the Weka feature selection functions CfsSubsetEval, ConsistencySubsetEval, Single-Attribute, and ClassifierSubsetEval methods.
The Correlated-based feature selection (CFS) assessors employed Rank Search Chi-Squared (RSCS), Greedy Stepwise-Forward (GSF), Greedy Stepwise-Backward (GSB), Rank Search Gain Ratio (RSGR), Best First-Forward (BFF), and First-Backward (BFB). Table 7 contains the results for CFS evaluators. Both generated a subset of flags with three features: bytesPerPacket, bytesPerPacket, and Durmsec. The three-feature set performs well, with AUC values of 0.650 for the five Group A classifiers and 0.650 for our Group B classifier, JRip. The F-measure had similar results for all the models, with JRip as the lowest with 0.963. The performance metrics of C4.5N and C4.5D had similar Type II errors with 14,777 and 14,788 for the three-feature set. NB and 5NN had slightly fewer Type II errors, with 14,390 and 14,750, respectively. RF had the least amount of Type II errors overall, with 13,060. By condensing the feature space to the most relevant features, the CFS feature selection technique achieves effective performance with fewer features, reduces the likelihood of overfitting, and speeds up processing. Five out of six classifiers are effective at detecting slow application-layer attacks using the three-feature subset.
Table 7 CfsSubsetEval resultsOur second attribute subset evaluator, ConsistencySubsetEval, used two search methods [Random Search (RS) and Exhaustive Search (ES)] and two options (forward and backward search). We denote these methods as, BFF, BFB, ES, and RS. ConsistencySubsetEval had favorable AUC results with the six classifiers as shown in Table 8. The 10-feature subset includes Packets, Bytes, SessionFlags, Flags, Durmsec, PayloadInBytes, PayloadRate, PacketsPerSec, BytesPerSec, and BytesPerPacket. The F-measure and correctly classified instances had similar results for all the models, verifying the predictability. NB had a significantly lower number of Type II errors with 1168, followed by C4.5D, C4.5N, RF, and the highest number of errors for JRip at 23,354. As mentioned previously in this paper, Type II errors are critical for predicting attacks on a network. With this ten-feature dataset, NB distances itself from the rest of the classifiers for detecting attacks on a network. The Consistency Feature selection substantially reduces the number of features that can differentiate among normal and attack data in relation to the four slow application-layer attacks: Slowloris, Slow Post, Slow Read, and Apache Range Header.
Table 8 ConsistencySubsetEval resultsThe four single-attribute evaluators, Gain Ratio (GR), Chi-Squared, Symmetric-Uncertainty, and IG, created a ten-feature set. The ten-feature set includes Packets, Bytes, Flags, InitialFlags, SessionFlags, Durmsec, PayloadInBytes, PacketsPerSec BytesPerSec, and BytesPerPacket. The difference between this ten-feature set and the previous is two features. The previous set included PayloadRate but not InitialFlags as compared to this ten-feature set. In reference to the four single-attribute evaluators, Chi-Squared produced the most favorable results, which are shown in Table 9. The ten-feature set performs well, with AUC values for the Group A classifiers and slightly less for the Group B classifier, JRip. The F-measure and correctly classified instances had similar results for all the models. NB again had a significantly lower number of Type II errors than all other machine learners with 607, followed by C4.5D, C4.5N, RF, and the highest number of errors for JRip 23,360. As mentioned previously in this paper, Type II errors are critical for predicting attacks on a network. NB had its best performance for Type II errors with 607.
Table 9 Single-attribute evaluator resultsThe Classifier Subset evaluator performed well with ten features as shown Table 10. They are Packets, Bytes, InitialFlags, Flags, Durmsec, PayloadInBytes, PayloadRate, PacketsPerSec, BytesPerSec, BytesPerPacket. This ten-feature set eliminated SessionFlags as compared to the previous two ten-features sets. The ten-feature set also shows good performance with AUC values for Group A classifiers, followed by Group B classifier JRip 0.656. The F-measure had similar results for all the models. Again, the performance metrics for C4.5N and C4.5D were similar. C4.5N had a slightly lower number of Type II errors than C4.5D, with 13,026 and 13,050 for the ten-feature set. RF and 5NN had slightly fewer Type II errors, with 13,025 and 13,060, respectively. NB consistently has the least amount of Type II errors overall, with 1085, while maintaining similar AUC and F-measure results.
Table 10 Classifier subset evaluator resultsTable 11 displays the results of six classifiers using PCA. We sorted the eigenvalues by decreasing significance and selected the eigenvectors based on the largest eigenvalues representing 95% of the variance in our dataset. We then used the new feature subspace from PCA with our six learners.
Table 11 PCA resultsThe PCA dataset had the best results with NB. It had the lowest value for Type II errors with 554 and slightly improved its AUC and FPR at 0.981 and 0.089. NB performs substantially better than all other learners in minimizing false negatives, demonstrating that it can better protect a network. PCA produced some noteworthy results. JRip, which had been significantly high with Type II errors, was similar to RF, C4.5N, and C4.5D, and 5NN had an improved AUC of 0.774, though it was the lowest. C4.5N, C4.5D, RF, and 5NN had similar Type I and Type II errors. False alarms account for roughly 40% of the alerts that cybersecurity teams receive daily. This number of false alarms can be overwhelming, as well as an enormous waste of time [53]. Training a new device and software is standard practice on the network for a predetermined duration [52].
ANOVA was used to examine statistically meaningful disparities among the six classifiers’ AUC values for multiple slow application-layer attacks. The F-value for Table 12 ANOVA is 739.874 and the p-value is less than 1.0446e−10. As with the initial AUC results, our results suggest that the variance of means between different learners is significantly more relevant than the fluctuation in mean values for all models.
Table 12 ANOVA PCA statisticsWe reject the null hypothesis once more. Our PCA results show that the differences between learners and multiple slow application-layer DoS attack detection are statistically significant. As illustrated in Table 13, the majority of groupings produced close pairings, with our models, RF, C45N, C45D, 5NN, and NB being assigned to Group A and JRip to Group B.
Table 13 Tukey’s PCA statisticsTable 14 displays how our five feature selection methods and Group A classifier performed using feature selection methods against the original twelve features. The acronyms from the table are CFS, Consistency Subset Selection (CON), Single-Attribute Selection (SA), and Classifier Subset Selection (CLS). NB had the best performance regarding Type II errors in four out of five feature selection methods. NB performed very well with SA and PCA for Type II errors with 607 and 554, respectively. These results reflect a significant difference as compared to the other five learners. When comparing NB results against the original twelve features, it more than cut in half the number of Type II errors when applying the PCA method. NB with PCA had the best overall performance for detecting multiple application-layer DoS attacks.
Table 14 Top feature selection method with classifier resultsWe collected all traffic on a live network using a Linux web server in order to analyze our aggregation of slow application-layer DoS attacks using Netflow data for the purpose of detecting slow DoS attempts. The capture generated Netflow data, which was examined by six machine learners to determine their ability to predict multiple slow application-layer DoS attempts. After that, we applied feature selection algorithms that proved effective performance with fewer features for discriminating between normal and attack data with our DoS attacks. As the findings demonstrate, feature selection datasets produced favorable performance ratings. When comparing Type II errors using feature selection approaches, there was a significant difference between NB and the rest of the Group “A” models.
In summary, Netflow can play a significant role in a network monitoring solution for multiple slow DoS attacks. One benefit of using Netflow is the speed at which an attack can be detected in real-time. This is critical and increases the chance of purging an attack before it does any damage. Netflow data is modest in size, which reduces processing time and makes it easier to read, analyze, and warn network managers when abnormalities and statistics are detected. If a learner achieves the same detection level with less data, this reduces the demand for CPU resources, increasing computational efficiency. Additionally, as a network scales in size, this becomes critical when using Netflow data. Combining Netflow with machine learners is efficient in detecting and alerting network security for multiple slow DoS attacks.
We realize that our methodology was not implemented and validated in real-time. This is one limitation that will be addressed in future work. Another limitation is the use of only one feature extraction method PCA. Future work will compare the use of PCA with other methods of feature extraction.
We suggested a method for detecting multiple application-layer slow DoS attacks by successfully utilizing machine learning and Netflow data. Four rounds of stratified five-fold cross-validation were used to calculate performance metrics. This research produces normal and attack traffic on a publicly accessible web server that is accessed by the campus community and the public at large. We give a more accurate depiction of the genuine network environment than previous testbeds by expanding our capture and including actual attacks alongside normal network traffic. Additionally, this strategy strengthens the integrity of our data by utilizing real-world traffic rather than related works that are not. We used the SlowHTTPTest software to conduct four unique attacks with varying modifications on each. The purpose of this experiment is to determine whether features aggregated from four separate slow DoS attacks are effective at detecting them.
Our investigation demonstrates that this technique for detecting multiple slow application-layer DoS attacks using features from Netflow data has a high AUC and a low percentage of false positives and negatives. For identifying multiple slow application-layer attacks, NB has the lowest Type II error rate. When we used feature selection approaches, we observed that the five Group A models had comparable acauc values and fewer Type II errors. NB used PCA to extract features from the original twelve features, resulting in the lowest Type II errors, and F-measure score of more than 90%, and an AUC value of 95% or greater.
Additionally, we demonstrated that all six learners performed admirably with Netflow data in detecting multiple application-layer slow DoS attack traffic, with five of them outperforming the remaining learner. As a result, machine learning models trained using Netflow features may successfully discern attack and normal network data across slow multiple application-layer DoS attacks.
Future work will conduct a cumulative and comparative evaluation of the detection and discrimination of multiple slow application-layer attacks using multi-classifiers and Netflow data. We will also further evaluate the impact that threshold adjustments can have on other performance metrics. In addition, the real-time implementation and validation of our approach will be investigated. Finally, future work will compare the use of PCA with other feature extraction methods to evaluate different intrusion detection models.